
So you’re moving your application to a web service API oriented architecture based on microservices. You’ve defined your endpoints to correspond to your application domain objects. You’re updating your applications to call these endpoints instead of making DB queries directly. Data access is now deployed in one place, instead of being spread across several applications.
Awesome.
But then you look up one day and find that you have to make a dozen, or perhaps even more, API calls in order to get all the data required to render a webpage. Things are slowing down, and complexity is increasing. What’s going on here? Isn’t this proliferation of web services supposed to make things better?
What’s a developer to do?
If you find yourself in this situation, here are three strategies you can apply when designing a web service API:
Check Granularity
A common pattern in API development is to create a set of endpoints that correspond to a specific domain object in your application’s data model. For example, an e-commerce site might might define a “user” service, a “shopping cart” service, a “product” service, and an “inventory” service. Each of these APIs correspond to a reasonably high level domain object in the overall data model of the application.
There is a fine balance here. Define the API too narrowly, and you have to make lots of API calls in order to get all the data needed. Define the API too broadly, and it becomes expensive to call and returns a payload that is too heavy for the most common use cases.
The key is to come up with the “right” level of granularity for your APIs. Determining what is “right”, is the hard part, but there are a few questions you can ask when deciding how big or small to make your API:
- How is the data is stored? If all of the data is stored in a set of related database tables, it doesn’t usually make sense to create multiple endpoints to access parts off that data. Just create one that returns all of the data for a logical record.
- Who uses the data? In many cases, the users of a set of data should help drive the development of an API. If everyone who asks for one set of data also needs some data from over there, perhaps this API should manage all that data and return it in a single batch to the caller.
- How often the data is needed? If you only need the data once a day, perhaps it doesn’t really matter if you have to make lots of API calls or wait for a really large payload to download. But if you need a bit of data multiple times a minute, then you’ll want the API to be as lightweight as possible.
Denormalize
Another approach is to take a cue from database development practices.
Wait? Database development? What does that have to do with web service API development?
Database normalization is the process of organizing your tables in order to reduce data redundancy. The full picture of a domain object can be seen by joining these associated tables together based on foreign key relationships.
Unfortunately, normalization sometimes introduces performance problems. Each time a query has to join to another table, the cost goes up. To counteract this, database developers will sometimes denormalize the data. That is, key bits of data are stored in more than one place so that an extra table join isn’t necessary. While this requires more work to keep the two places in sync (for example, using triggers), the performance gains are, typically, worth the extra developer aggravation.
This same idea can be applied to the microservice API level as well. Suppose Application A needs a view of the data managed by Application B. With a normal approach, the data access might look something like the following diagram, where Application A makes a call to Application B to get it’s data.
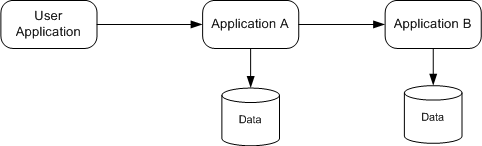
However, in the name of efficiency, it sometimes is makes sense for Application A to listen for changes from Application B (e.g. via a messaging system) and store a copy of the relevant data in Application A’s data store. This way, Application A has the full set of data it needs to serve it’s API endpoints. Application B only needs to be called if a more detailed view of the data is needed.
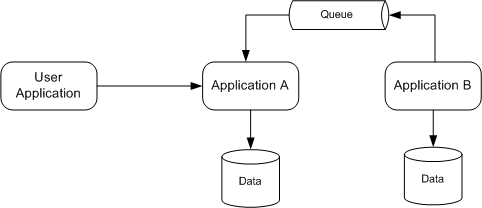
For this to work, you’ll need to get comfortable with the idea that your applications will be eventually consistent. This doesn’t work if you need data changes to be performed in a single, two-phase commit, database transaction. However, this notion of atomic commits is a fairly recent development in human history. To paraphrase Neil Ford, when talking about how bank checks used to be reconciled back in the day of the Pony Express, “There is no two-phase commit when there is a pony involved.”
Compose in Parallel
Often, you may have multiple consumers that all need to call the same sequence of microservices in order to display some data to the user. For example, a mobile app and a web application both need to call the user service to get account information as well as the rating & review service to get the list of that user’s reviews.
In this case, it often makes sense to build a composite endpoint, also called an orchestration service. This API takes care of the work of calling all the other endpoints needed to build the full view of the data needed. This approach gives you the benefits of calling a single API without having to have every application figure out which services to call.
This composite endpoint will also, likely, cache the results of the API calls it delegates to. While this may be needed for efficiency reasons, it comes at the cost of complexity, as it requires a mechanism to make sure the cache doesn’t go stale. This could be as simple as flushing the cache on a frequent enough basis or as complex as listening to an event stream and flushing the cache as specific events come in.
Whether you compose your APIs or not, try to run your web service API calls in parallel. Often, the multiple API calls are not dependent on each other, so run them all in separate threads and wait for them all to complete. This means that your total request time is only as long as the slowest API call.
Conclusion
The next time you’re questioning your sanity for moving towards a service oriented model for your application, take a look at your APIs and how your calling them and make sure you have the right granularity, are composing APIs when appropriate and calling things in parallel when possible.
Question: What problems have you encountered while moving towards a service-based architecture? What have you learned to make things run better?